Sample size inflation tests¶
These tests are designed to explore the idea of increasting the posterior sample size during the course of the fitting. The theory is that we can start out with a small sample size which is very fast and will get us close to the optimal cost, then the size is increased to get a more accurate sample from the posterior and refine the optimization to be more accurate.
In principle this should be faster than simply using the larger sample size from the beginning and may also help to avoid local minima by encouraging a ‘noisier’ initial optimization.
There are two key questions we need to answer when exploring this strategy:
- What combination of initial sample size, final sample size, and number of training epochs is required to ensure we achieve convergence sufficiently close to the actual minimum cost for the data?
- For combinations which achieve within some given tolerance of this cost, which get there in the shortest time?
Tests using ASL data¶
These tests were performed using the multi-repeat ASL data described here. We compared initial sample sizes of 2, 4, 8, 16, 32 and 64 growing to final sample sizes of 2, 4, 8, 16, 32 and 64 over 100, 200 and 500 epochs respectively.
The following plots show the minimum cost achieved for each combination of initial and final sample size at each number of epochs (the two plots show the same data but one is focused on comparing initial sample sizes for a given final sample sizes and the other is focused on comparing final sample sizes for a given initial sample size):
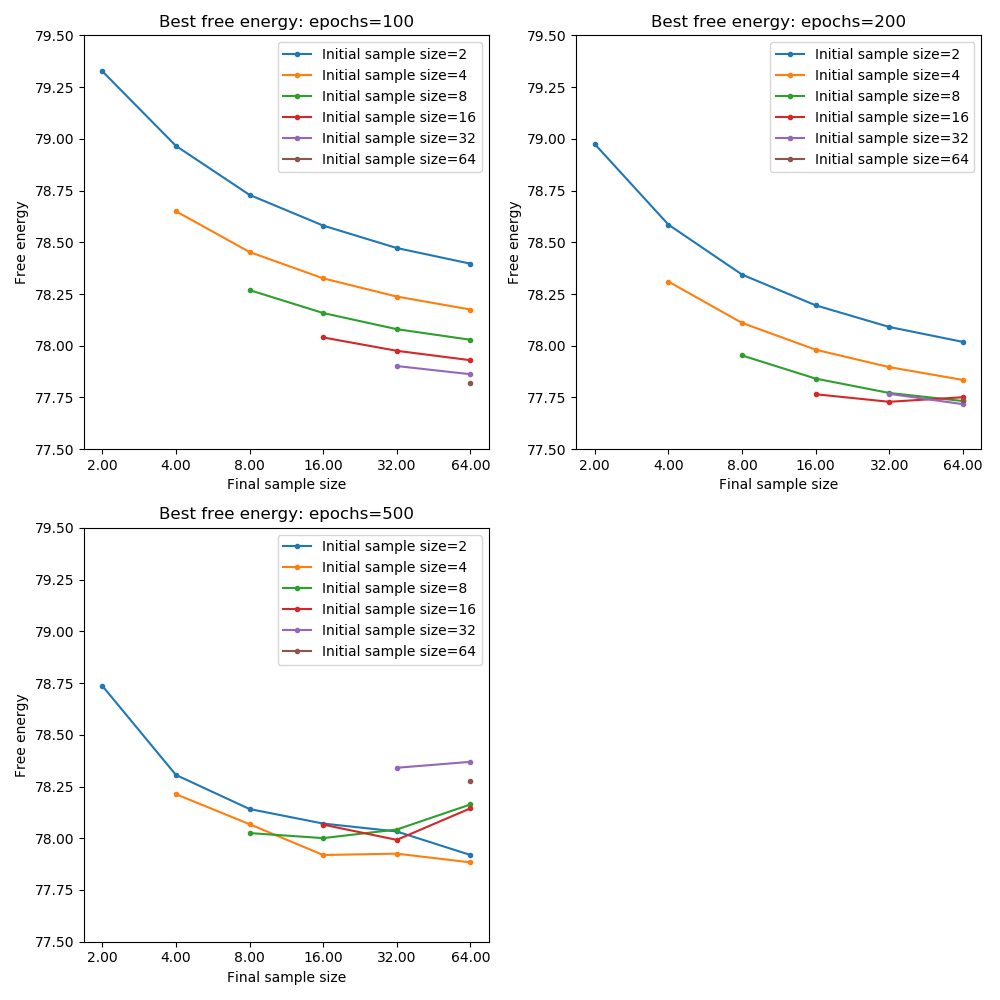
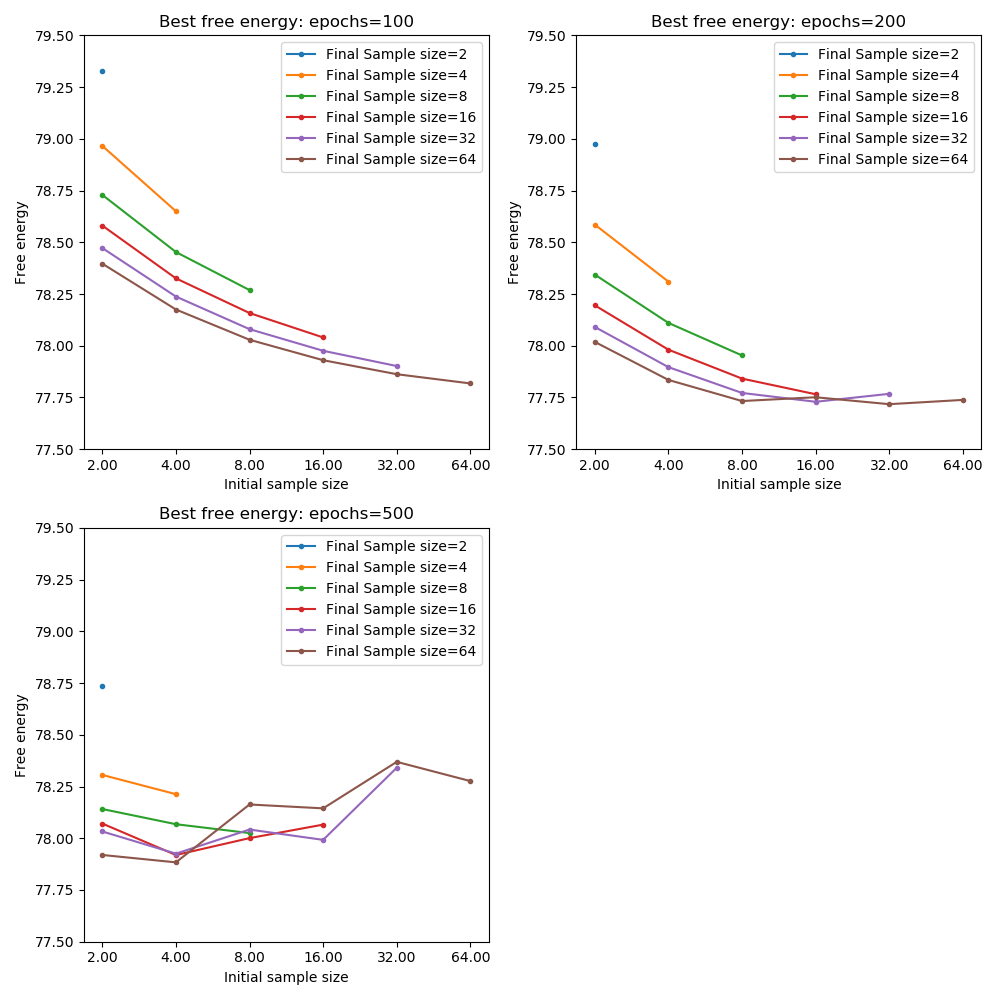
From these plots we can see that with only 100 training epochs we are not yet at absolute convergence even using the maximum sample size throughout. For 200 epochs, we achieve close to the optimal cost when the final sample size is 64 or 32 and the initial sample size is at least 8.
The following plots show the time taken to reach within a given tolerance of the best free energy for combinations of initial and final sample sizes. We only consider final sample sizes of 64 and 32 based on the previous results:
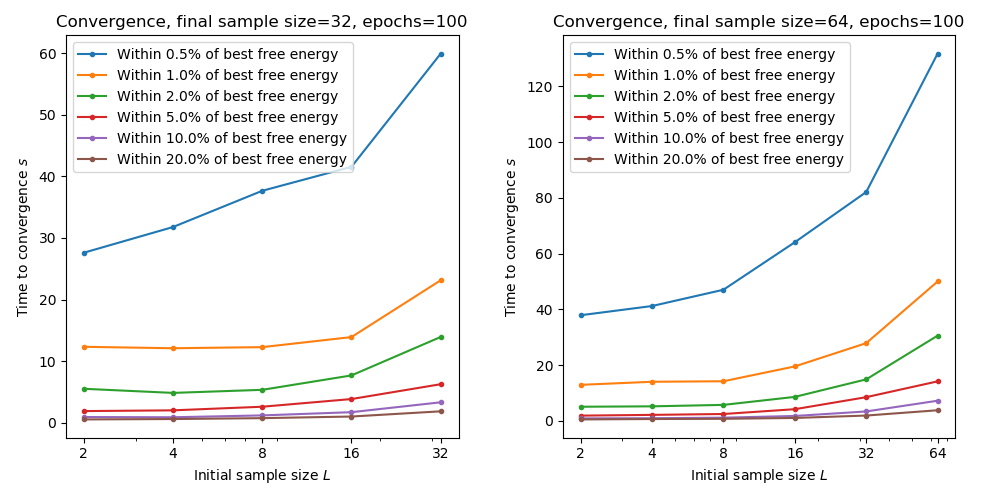
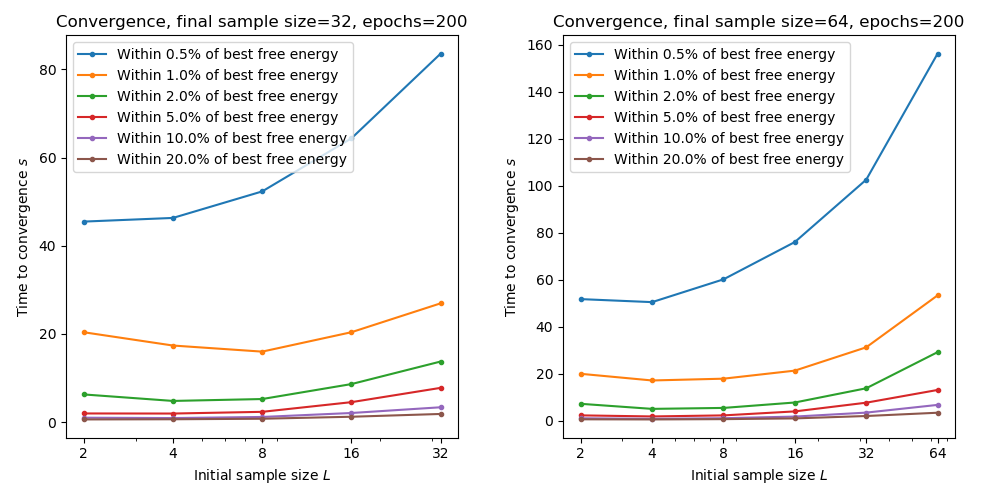
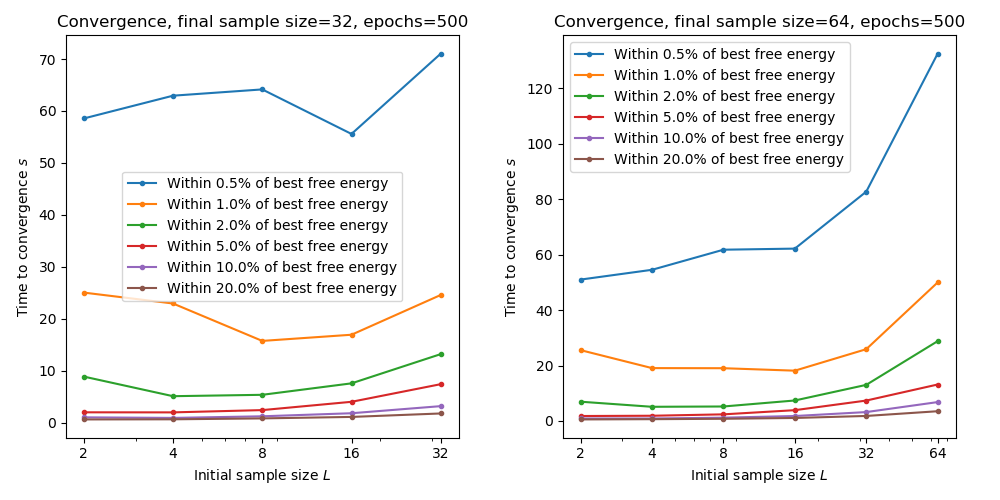
Here we see that starting with a smaller sample size is generally associated with faster overall convergence. For this data we would recommend an initial sample size of 8 and a final sample size of 64.