Learning rate quenching tests¶
These tests are designed to explore the idea of decreasing the learning rate during the course of the fitting. The theory is that we can start out with a high learning rate which rapidly converges close to the optimum, but then reduce it over time to get as close as possible and avoid the problem of large steps overshooting the minumum.
In principle this should be faster than simply using the lower learning rate throughout since the initial move towards the neighbourhood of the minimum should require fewer epochs. In addition if the initial learning rate is very low then the optimization may fail to escape from local cost minima that exist close to the initial values.
There are two key questions we need to answer when exploring this strategy:
- What combination of initial learning rate, final learning rate, and number of training epochs is required to ensure we achieve convergence sufficiently close to the actual minimum cost for the data?
- For combinations which achieve within some given tolerance of this cost, which get there in the shortest time?
Tests using ASL data¶
These tests were performed using the multi-repeat ASL data described here. We compared initial learning rates of 0.8, 0.4, 0.2, 0.1, 0.05, 0.025 and 0.0125 with reduction over the training cycle to final learning rates from the same set (but only running examples where the final learning rate was less than the initial. The training cycle was performed over 100, 200 and 500 epochs.
The following plot show the minimum cost achieved for each combination of initial and final learning rate at each number of epochs (the two plots show the same data but one is focused on comparing initial learning rates for a given final learning rates and the other is focused on comparing final learning rates for a given initial learning rate):
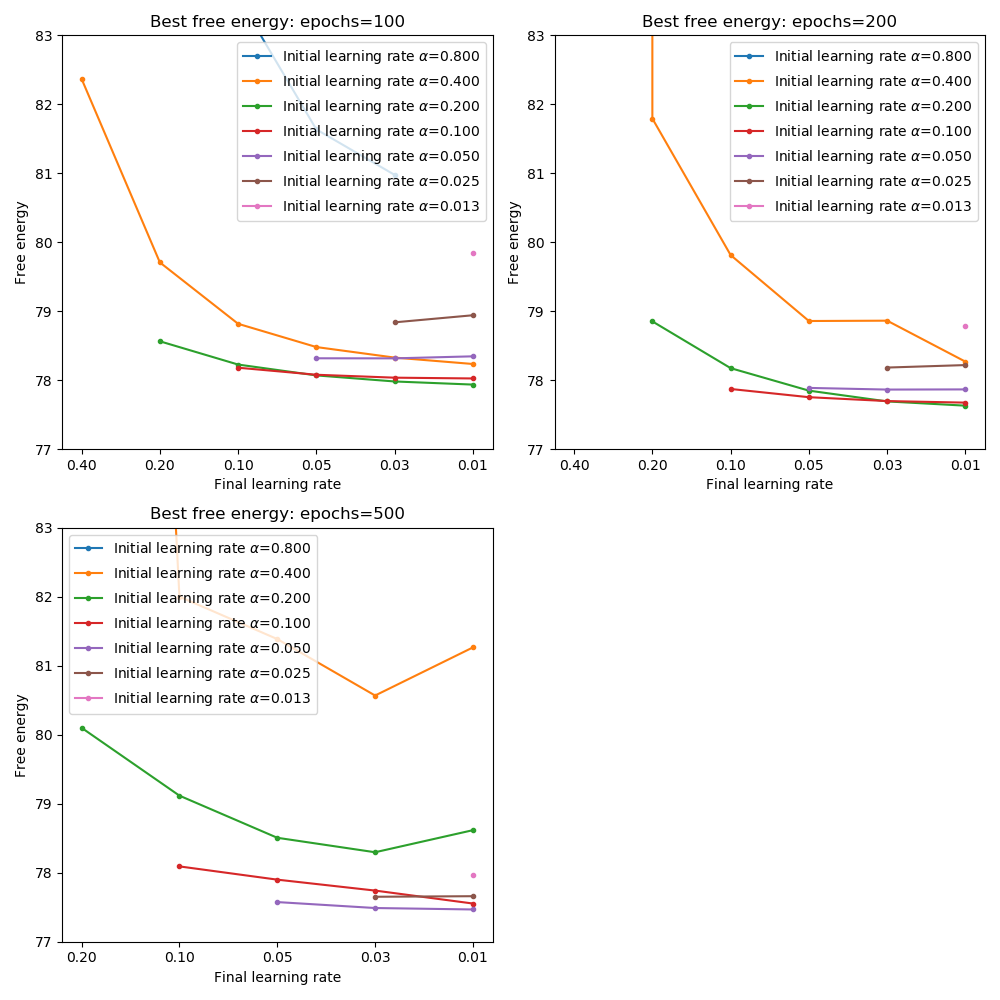
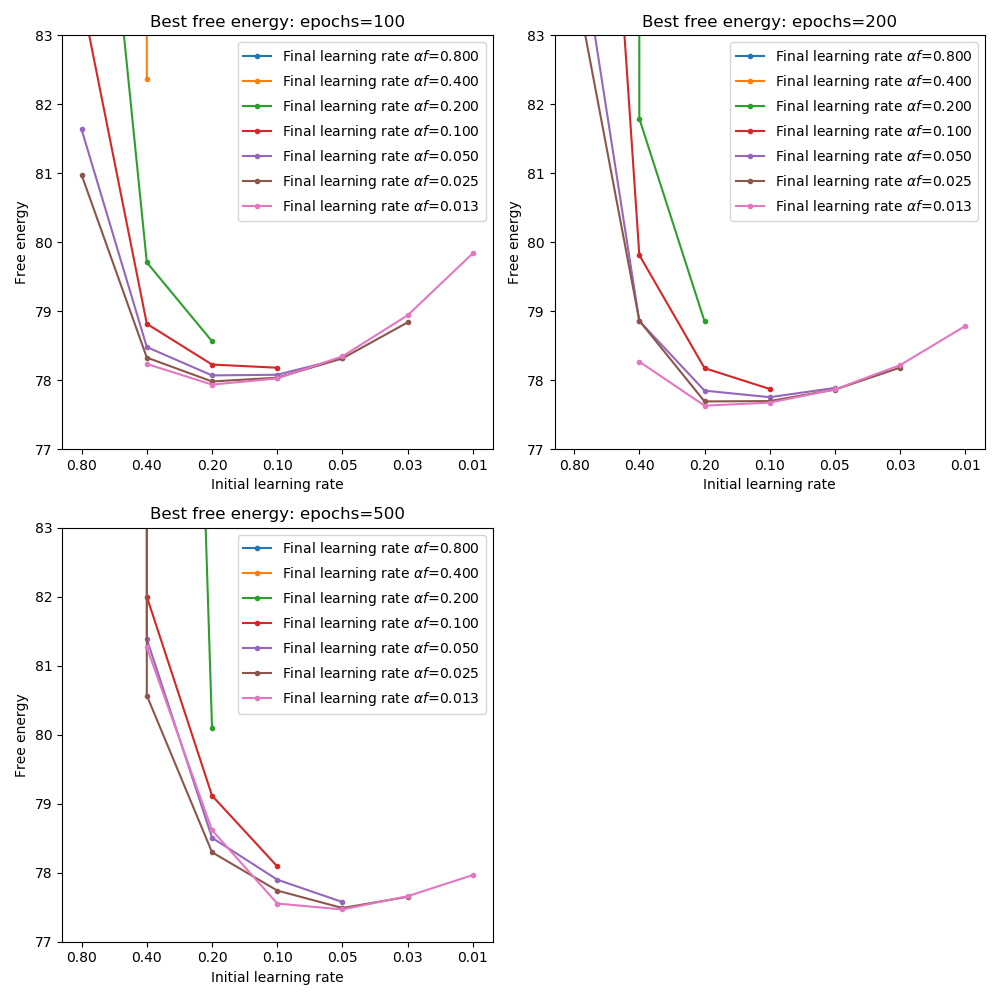
From these plots we can see that with firstly the minimum cost is achieved only when the final learning rate is sufficiently low - this confirms that a low learning rate is necessary to accurately home in on the minimum without overshooting.
Furthermore, a better cost is achieved by starting at a higher learning rate - 0.2 to 0.1. This is the case even with 500 epochs of training. So the general strategy of starting out with rapid learning and quenching to a very low value seems to be a good one.
It is noticeable that we obtain worse cost over 500 epochs than over 200 epochs when the initial learning rate is high. It may be that maintaining a high learning rate for too many epochs leads the optimization far away from the optimum. This is confirmed by the actual runtime free energy which starts out by reducing but rapidly begins to oscillate between high and low values if the high learning rate is continued.
Best cost over 100 epochs was 77.9 (initial 0.2 -> final 0.0125). Over 200 epochs the best cost was 77.6 (same combination) and over 500 epochs the best was 77.5 (initial 0.05 -> final 0.0125).
The following plots show the time taken to reach within a given tolerance of the best free energy for combinations of initial and final learning rates. We only consider final learning rates of 0.1 or lower as previous plots show that we are not close to convergence when then final learning rate is higher:
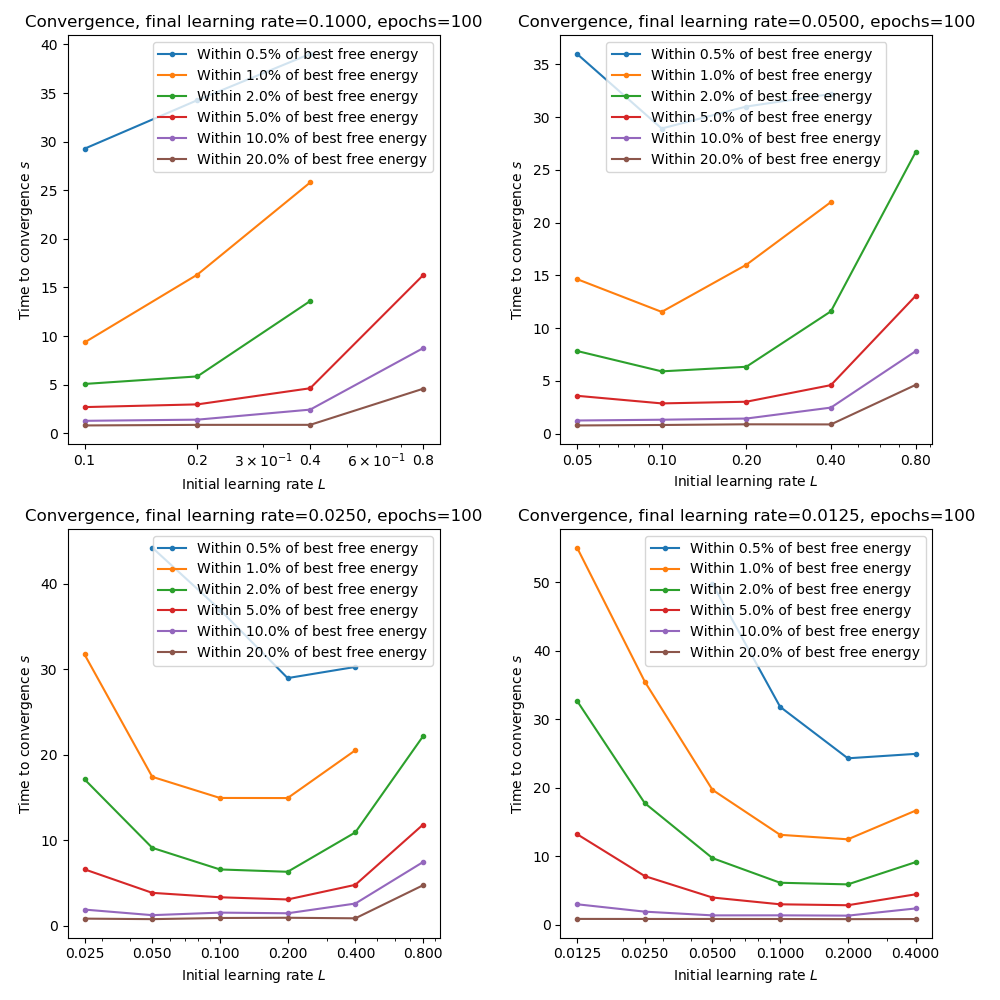
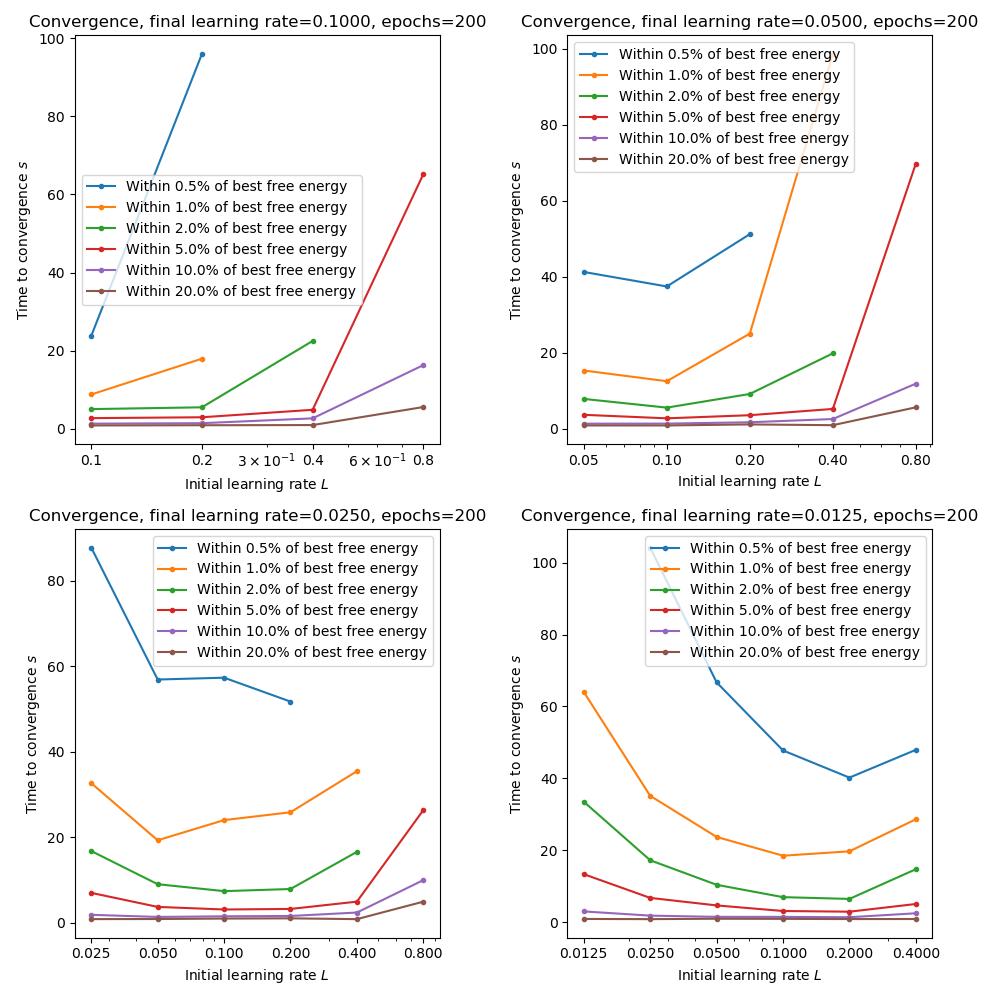
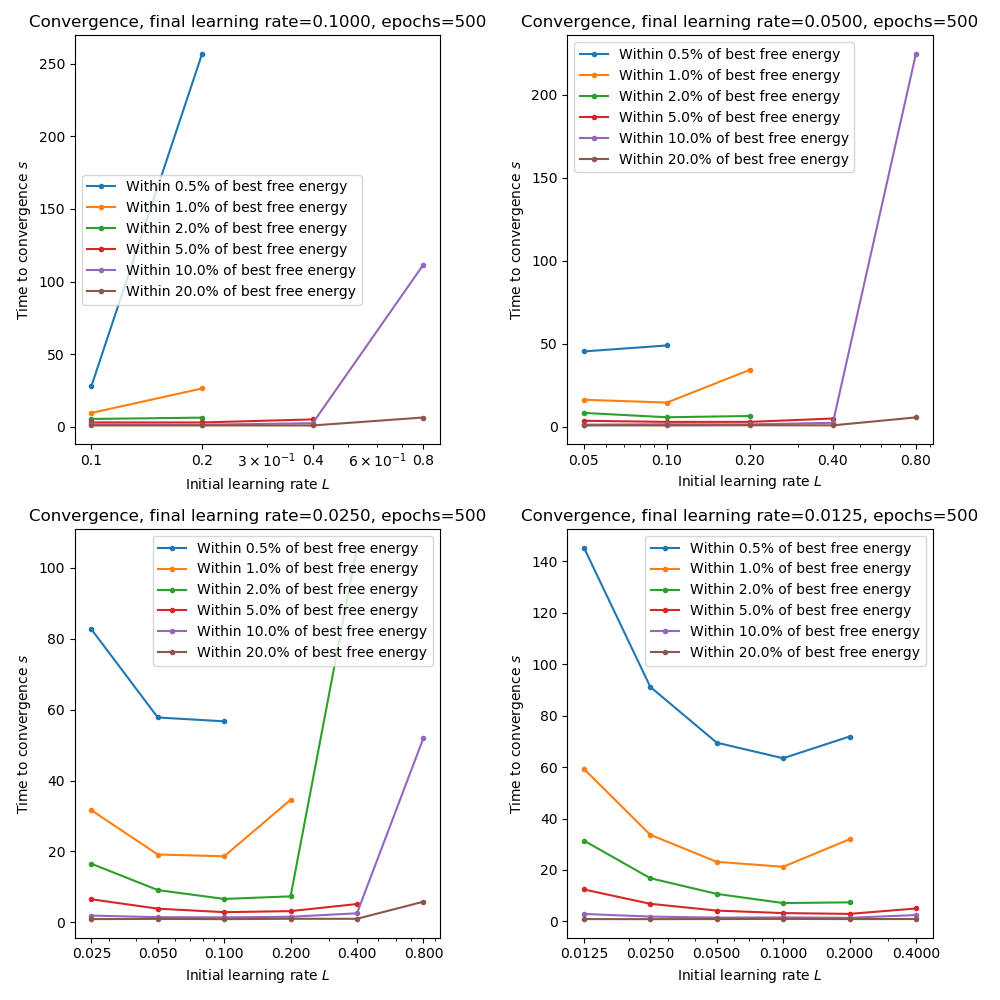
These plots show that starting with a high learning rate can indeed accelerate convergence provided it is quenched rapidly. Slow quenching (e.g. from 0.2 to 0.1) seems to leave too many training epochs at the higher learning rate and can reduce the convergence speed.
It’s worth noting that the computational time per epoch is largely independent of learning rate, so these measures are essentially measures of how many epochs were needed for convergence (unlike with sample size inflation where the training time increases as we increase the sample size). So slower convergence can be a result of too much time initially at a low learning rate (where the optimizer slowly ‘inches’ its way towards the minimum) or alternatively too much time initially at a high learning rate, where the optimizer repeatedly overshoots the minimum until the quenching process lowers it sufficiently to converge.
For this data and appropriate combination seems to be 200 epochs starting at 0.2 and reducing by a factor of 16 to 0.0125. This gives a cost very close to the minimum and also optimizes the convergence rate measure.